Don’t design for AI – Fromer Media Group
[ad_1]
Design for problems worth solving with AI, distributed cognition, cognitive strategy prompts and human centered design
How often have we been approached by a client to “do the AI” in a project… with the expectation that some (generative) AI might “magically” solve all known, unknown, and mostly undefined problems?
https://medium.com/media/fc51ccceb9175cc5a68346b005c3282f/href
In this opinionated article, based on a talk at UX Live 2023 by Jacqueline Martinez and Johannes Schleith, we propose tweaking design thinking methods for opportunity detection.
When you have a Large Language Model, everything looks like an opportunity for a chat-based assistant …
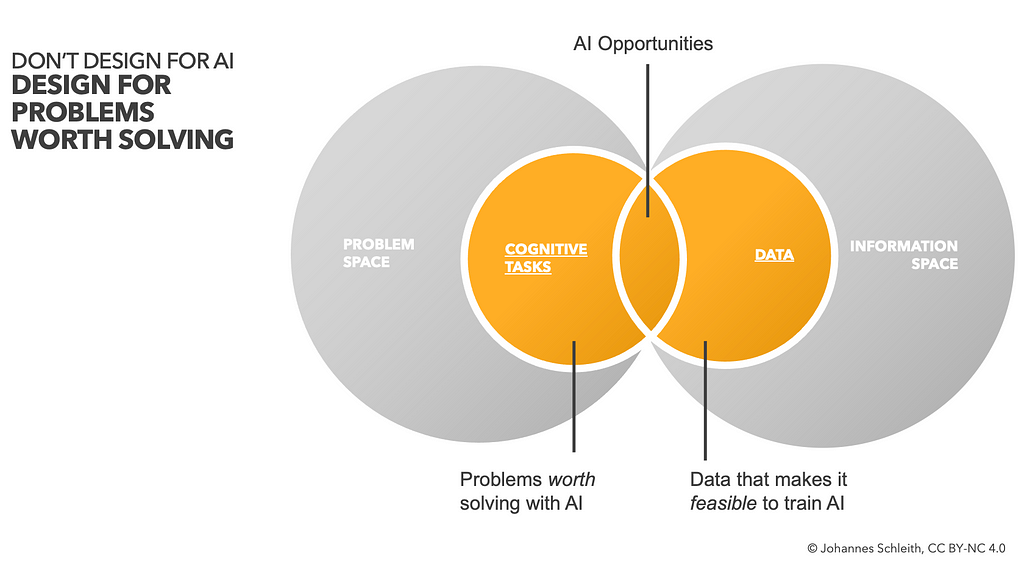
Design for problems worth solving!
Let’s go back to the design basics. Rather than jumping to solutions, a well-structured problem-led approach aims to investigate and clearly define problems (Problem Discovery), prior to experimentation with various possible solutions to those problems (Solution Exploration).

Not every problem needs to be solved with AI. Not every AI opportunity needs to be solved with a Large Language Model (LLM). Focusing on the problem first allows to explore alternative solutions, benchmark and evaluate them and pick the most suitable solution.
With that in mind, we propose to structure AI opportunity detection with frameworks such as distributed cognition and cognitive strategy prompts, and conduct user research and data landscaping in parallel. We’ll define these terms below…
Design for Distributed Cognition!
In a nutshell, Distributed Cognition is an established Human Computer Interaction (HCI) framework, which allows teams to take on a holistic perspective beyond technology and software. One of the key ideas is that “cognition” is not limited to human brains only, but an emergent property that is dispersed across people, artefacts and technologies.
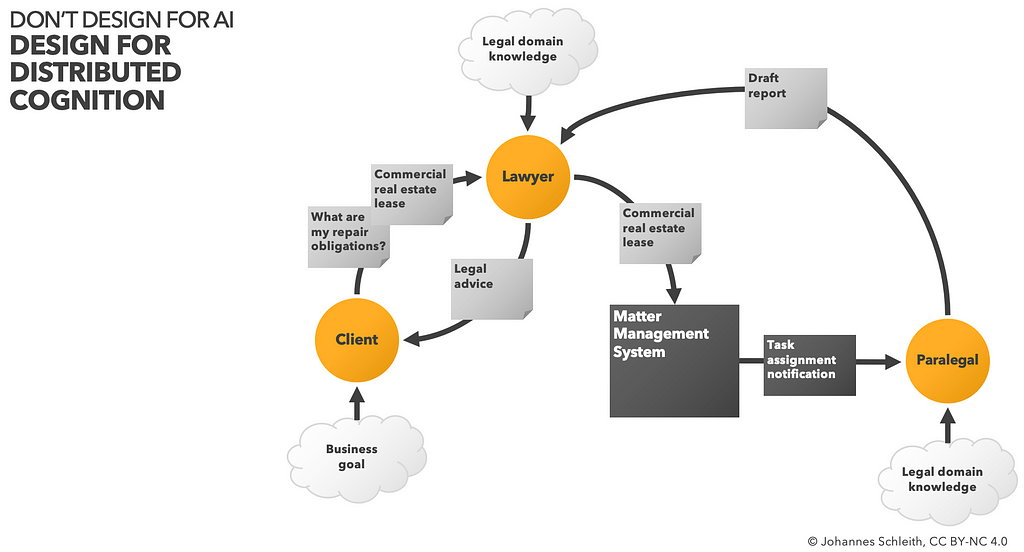
In our illustration, client, lawyer, matter management system and paralegal are collaborating, in order to satisfy the initial client request. Each actor uses their knowledge (business, legal, data) in order to manipulate the available data, provide cognitive services (review, summary, advice) and ultimately generate legal advice.
It can be quite tricky to fully describe a complete picture of such collaborative systems. However, user research and systems thinking methods can helps us understand and map processes, goals and describe in detail how actors collaborate and “think together”.
Once we understand the system, we can detect AI opportunities!
Design for Cognitive Tasks
In order to map the process of distributed cognition, we capture the expected input, desired output, and core jobs-to-be-done (JTBD).
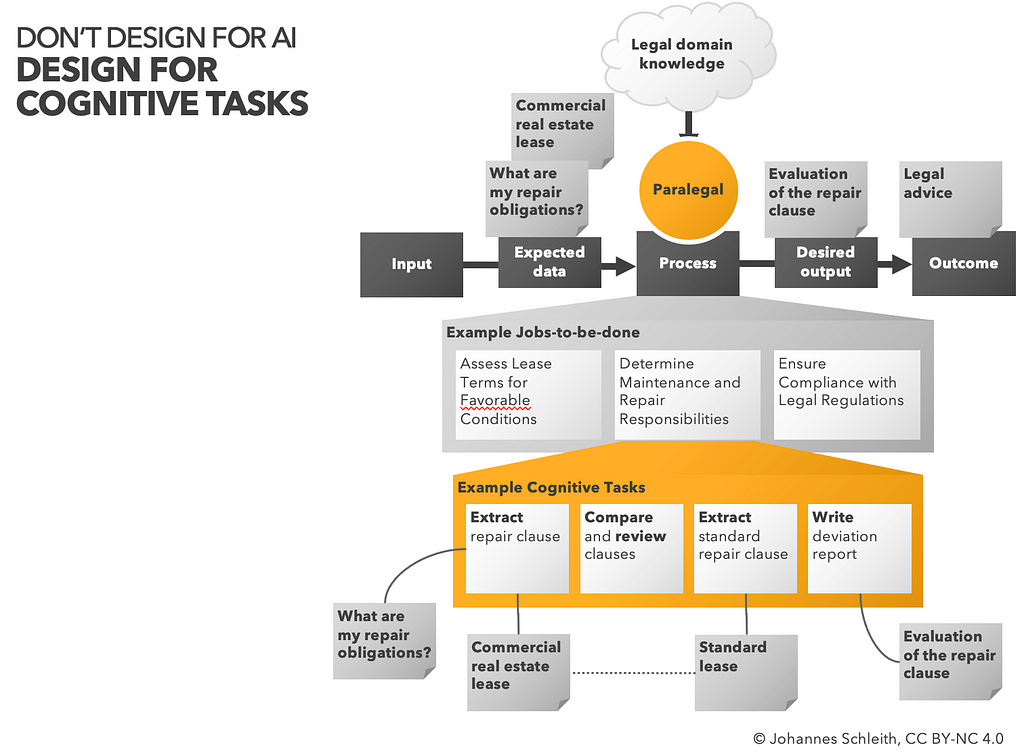
In a second round, we try to reframe JTBD into “cognitive tasks” through a number of cognitive strategy prompts. We might ask what kind of “information handling” activites are involved in the process, whether jobs are related to search, lookup, review, contrasting or relation of information?
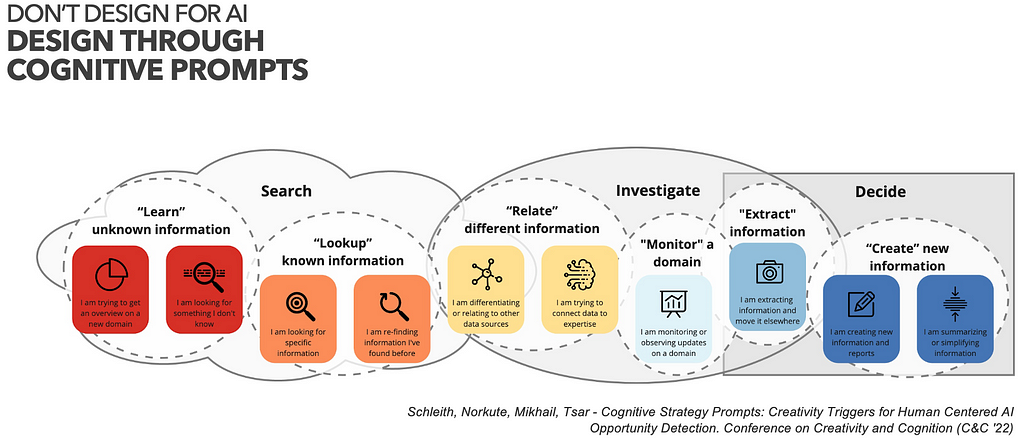
We found that application of the prompts can significantly increase the number of ideas that are AI relevant, because they nudge ideation towards activities that can actually be supported with AI methods.
Now that we understand the process, information and cognitive tasks, its about time to look into the data that can be used for experimentation
Design based on the Data Landscape
We can (user) research and design all we want, if we ignore the constraints — or opportunities — of underlying data we will not create successful AI powered innovation. After all, AI is only as good as the data you train it on.
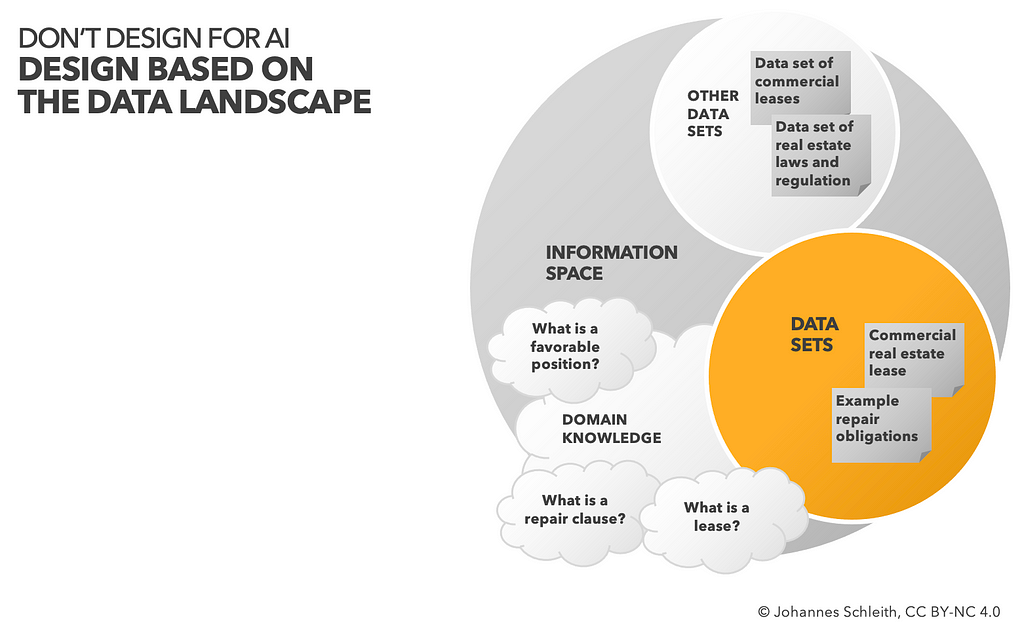
Inspired by the Disruptive Design Method we aim to get a holistic, system level view on the landscape of all information involved in our use case. What data are available? How can they be accessed? What specific data formats are relevant to our use case?
We might explore beyond whats in front of our eyes and think about what other data sources that we haven’t considered yet might be relevant?
Often “information” that is highly relevant to a use case is not actually present in digital data — but resides in individuals heads, in the form of domain knowledge.
For example, in legal tech innovation, domain experts are highly trained individuals with rich taxonomies, precedent cases and matters deeply memorized in their human brains. Its crucial to be aware of such “data” and consider how to enable end users to bring in their very own expert view.
We are now ready to transform our AI opportunities into hypotheses and experiments.
Why experiment?
How much resource is wasted by locking-in to one specific technology or concept too early, while missing to evaluate product market fit and ignoring alternatives?
Even if you run as fast as you can, if you are going in the wrong direction, you’ll fail!
https://medium.com/media/55b1c89ab46c941fe4cae4475f09f44f/href
Reframe Data Science Problems
First, we want to reframe what we know about cognitive tasks as data science problems. Data science is what makes AI work and tick. So let’s map user needs to specific data science problems. Data science
The better we can define expected input data (e.g. real written reports that need to be summarised), its manipulation and desired output (e.g. some real report summaries), the easier it is for data scientists to work through some experiments.
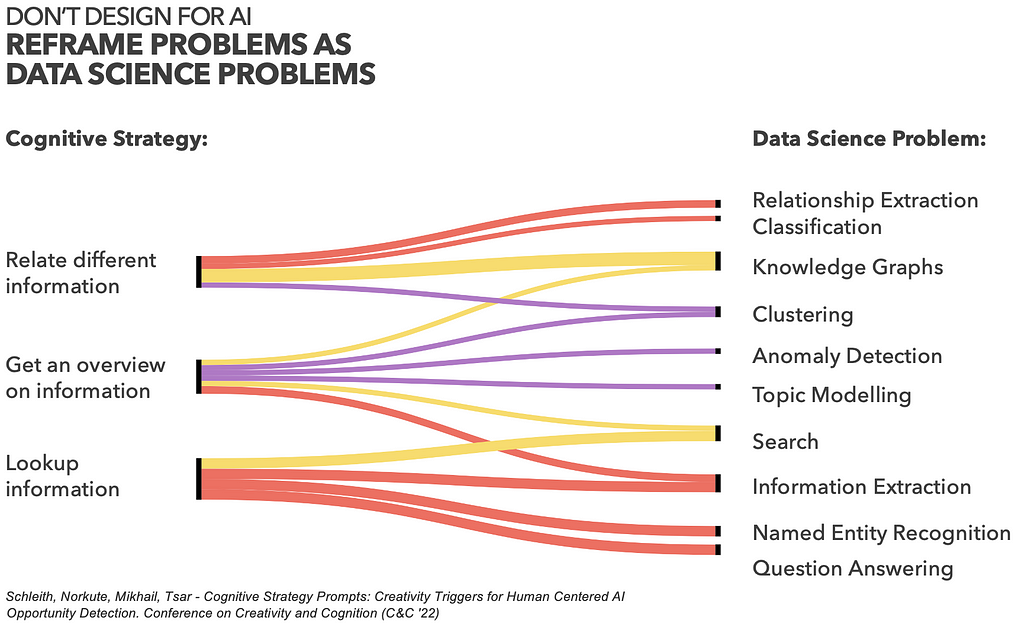
For example, imagine that a legal researcher wants to “get an overview on information”, related to a legal case, their client’s industry or a new practice area they are working on — we could assist this task with various data science methods — depending on what our data allows for — e.g. knowledge graphs, clustering techniques, anomaly detection, topic modelling and so on
While our paper explored a mapping between prompts and data science methods, such mappings will always be incomplete due to the ever evolving AI methods and their surprising emerging qualities. It is crucial to involve data scientists early in the ideation process — precisely define the problem for them and work through various alternative solutions, so that we can evaluate different ideas and hypotheses and select the best fitting solution to our problem.
“AI is not one thing […] it’s only AI until you understand it — then it’s just software”
Design for Human Centered AI
Human centred design for software products is table stakes. Many successful products have been built with a strong focus on user experience and usability. The same should be true for AI powered products.
Human Centered AI (HCAI) is an emerging and quickly evolving field. that prioritizes human aspects like human control, human-in-the-loop and feedback loops, trust, error recovery, explainability, and many more.

When exploring alternative solutions to a well-defined problem, during a conceptual design phase, it is worth working through some of these aspects and consider how to optimize the design for them.
For starters, this can be as simple as taking a conceptual prototype or wireframes into a working session and thinking through one theme at a time, and how to optimize for such a theme.
Let’s look at two examples: Explainability and Human-in-the-loop.
HCAI Example: Design for Explainability
A great example is the 2021 paper by Norkute et al. on explainability for a text summarisation solution. The team experimented with methods to summarise multiple pages of legal cases into one (or a few) sentences. The goal to optimize the system for explainability made the team of researchers consider and evaluate alternative approaches to explain how the system had generated each summary.
While one explanation of the generated summary used an off-the-shelf explainability method that highlighted the section that was most important source for the summary, another method put more effort into calculating attention vectors and highlighting a heatmap of words that were most relevant for the summarisation. Both approaches could be evaluated and A/B tested.
Note that the best explanations do not go into unnecessary detail, but provide some easy-to-grasp layer of communication that gives the user an idea of how the system might behave. On the flip side, over-explaining with too much (technical) detail can easily overwhelm non-technical end users, and might be confusing rather than helpful.

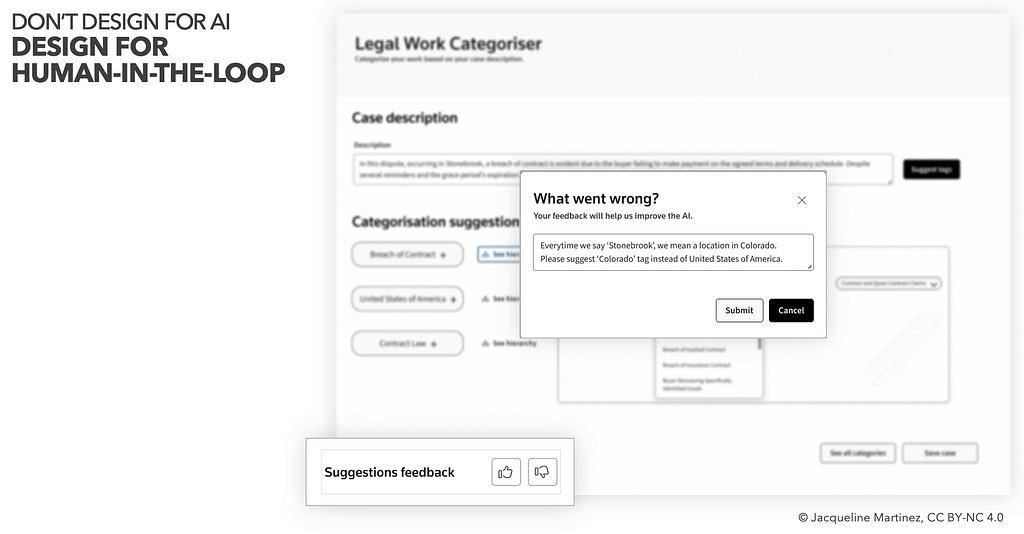
HCAI Example: Design for Human-in-the-Loop
In his book Human Centered AI, Ben Shneiderman showed that increased levels of autonomy by the system, do not necessarily have to mean decreased levels of control by a human.
Alongside optimizing for explainability, it is worth to consider ideation on concepts for feedback loops. Often it is crucial to keep human end users informed and up-to-date about the current behaviour of the system — or provide detailed audit trails and logs to monitor decisions by the system in hindsight.
Always keep in mind that, while seemingly intelligent, AI systems are nothing other than statistical machines that easily mistake meaning of words or symbols that violate common sense.
Design for hypothesis testing
Each idea, how we might reframe a cognitive task as a data science problem, is essentially a hypothesis we can test!
Depending on your team size, you can be more or less formal about defining hypothesis, expected input data, desired output data, core jobs to be done to support, desired outcomes for the end user etc. etc. Data scientists can then experiment with various data science methods and AI methods — as long as they are provided with relevant (training) data.

For example, Strategyzer’s test card is an easy to grasp artefact that can be used to reflect on and discuss hypotheses and experiment to evaluate them in a workshop session.
Prototyping for Dynamic Content
In addition to technical proof of concepts, we might also want to test hypotheses with domain experts and end users through rapid prototyping and concept testing.
While Machine Learning is a “new design material”, prototyping with data and dynamic content brings its very own challenges. Current design tools (e.g. Figma, Framer, Sketch, Axure etc.) are fantastic to prototype and test user journeys — as long as the content within these journeys remains static. In contrast, often the very thing we want to evaluate is the quality of the machine generated, dynamic content.
UX professionals need to play with code and get their hands dirty!
It’s worth working closely with data scientists to test their early results, either straight out of the computer terminal, Jupyter notebook, plotly data visualisation or wrap a simple Streamlit application around their python functions.
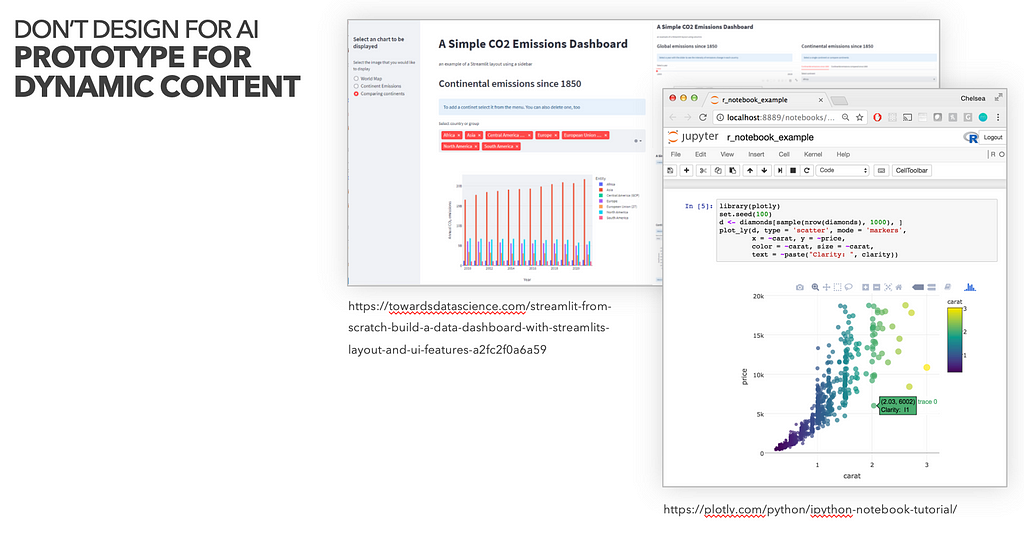
User testing straight out of such prototypes allows to evaluate the AI algorithms’ output and can be combined with UX prototypes that tell the story of the product around the content. Early evaluation often also inspires design changes to find a conceptual solution that better fits the dynamically generated content.
Where this is not possible, good old HCI techniques like Wizard of Oz, Concierge testing or similar, can go a long way to provide useful end user evaluation in early stages of a project.
Aspects to test for might encompass perceived trust, perceived control and usability, perceived capability and intelligence, and address the ultimate question of how a new AI-powered product might fit into the end users day-to-day.
To wrap things up. We recommend to tweak design process and methods in the following way…
- a good understanding of how distributed cognition happens throughout the system or use case under investigation.
- a clear focus on “cognitive tasks” and “information handling” in specific processes related to core jobs-to-be-done
- a data inventory and understanding the constraints of available and accessible data sets
- detect AI opportunities through a focus on distributed cognition and cognitive tasks, in conjunction with an open minded data inventory
- reframe user needs into data science problems
- design for Human-centered AI and prototype with dynamic data to test your hypotheses
We hope this mini series was useful to you. Let us know in a comment, whether you agree, challenge any of the points or want to add any thought!
Read more:
Don’t design for AI was originally published in UX Collective on Medium, where people are continuing the conversation by highlighting and responding to this story.
[ad_2]
Source link